
Time Can Be a Lie: How Clocks Break Distributed Systems
The clock is a fact on one machine and an opinion across many. Here's why — and what the best systems do about it.


Every program you have ever written trusts the clock. You ask the computer what time it is, it tells you, and you believe it. For most code on one machine, that trust is fine.
The moment you have more than one machine talking to each other, that trust quietly breaks. The clock becomes one of the most dangerous things in your system — not because it stops working, but because it keeps working while being slightly wrong, and slightly wrong is enough to cause real outages.
This post is about why that happens, told in plain language, with real stories.
First, what is “the clock” anyway?
Inside almost every computer is a tiny crystal — usually quartz. When you run electricity through it, it vibrates at a steady frequency. The computer counts those vibrations to keep time, the same way a wind-up wristwatch counts the swings of a tiny wheel.
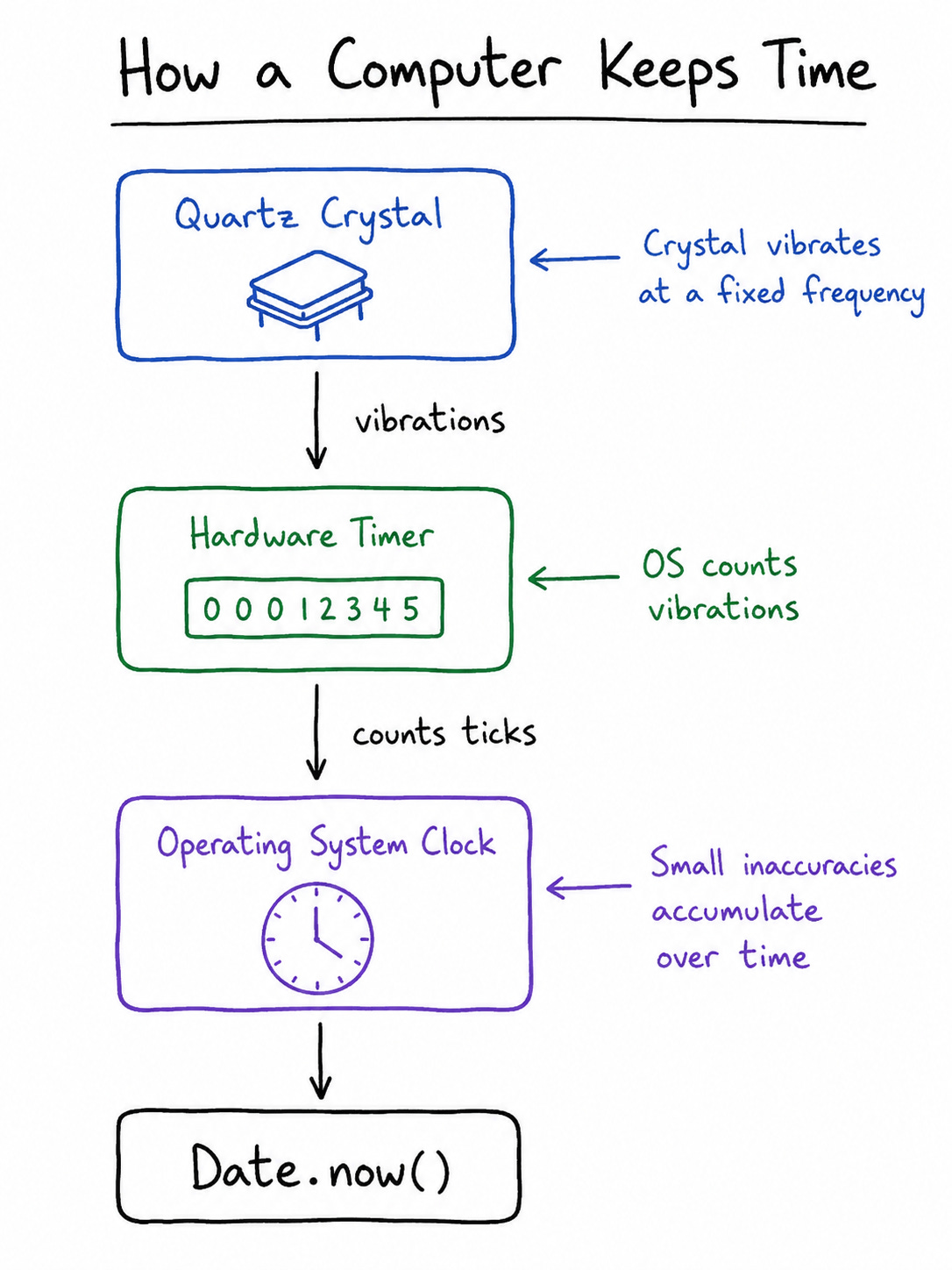
Here is the first problem. No two crystals are identical. Temperature changes them. Age changes them. Tiny manufacturing differences change them. So one machine’s crystal vibrates a hair too fast, and another’s a hair too slow. This slow wandering is called drift.
Drift sounds harmless because the numbers are small — often a few parts per million. But “a few parts per million” works out to seconds of error per day. Two servers that agreed perfectly at noon today can be several seconds apart by next week. They are both convinced they are right.
But how does it remember the time when it is switched off?
Here is a question that sounds silly until you actually think about it. That crystal we just talked about only ticks while the computer has power. So when you shut your laptop down at night, and the whole machine goes dark, what is counting the hours until morning? When you boot it up, it somehow already knows the correct date and time. Where did that come from?
The answer is that there is a second, completely separate clock inside your computer, and it is built for exactly this job. It is called the Real-Time Clock, or RTC — a tiny, dedicated chip on the motherboard whose only purpose is to keep track of the calendar.
What makes it special is that it has its own power supply: a small coin-shaped battery (the silver CR2032 you may have seen if you have ever opened a desktop). That battery keeps the little RTC chip ticking quietly even when the computer is unplugged from the wall — for years on a single battery. The main processor sleeps, the fans stop, the screen is black, but in one corner of the board this minuscule clock keeps counting, sip by sip of battery power.
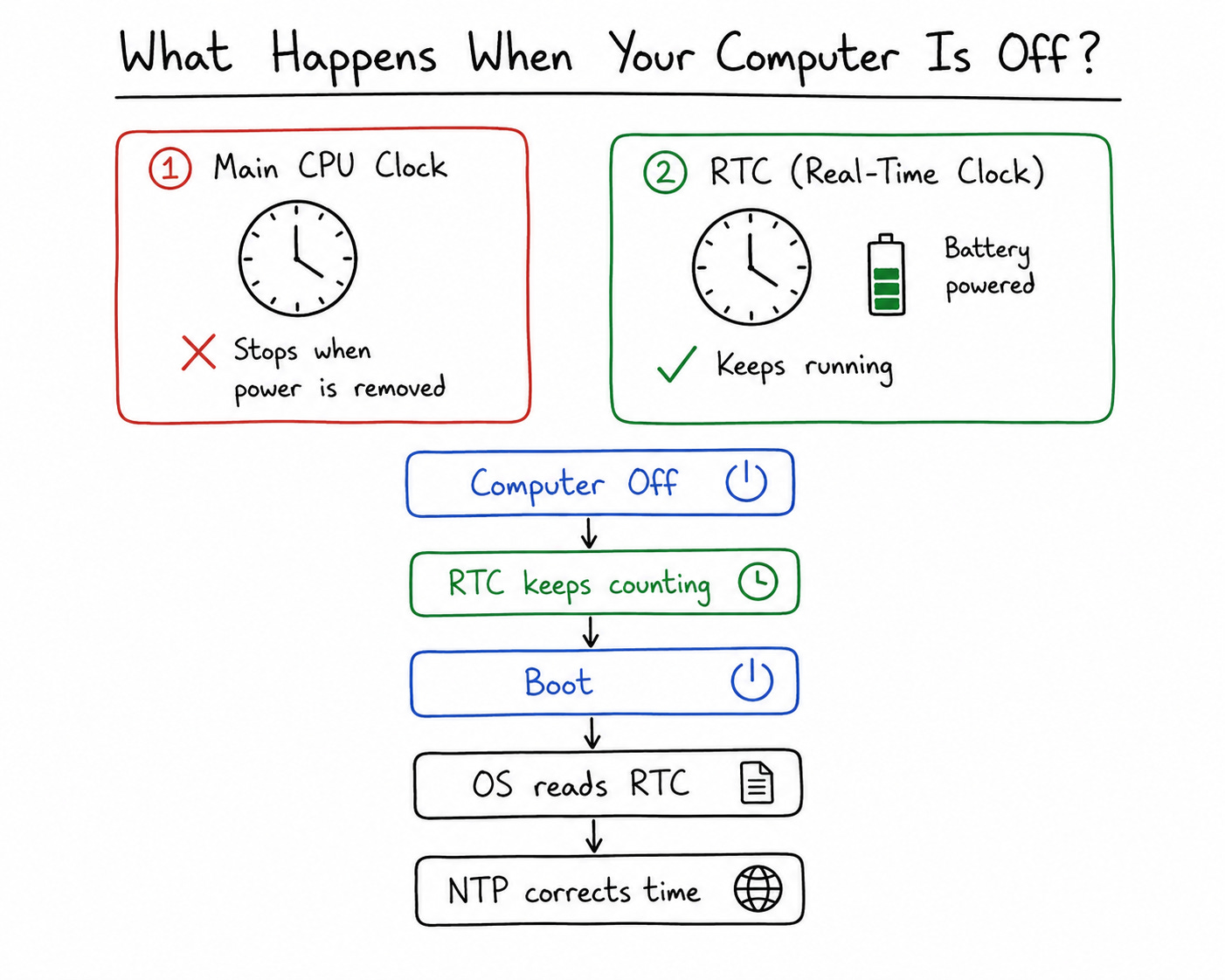
So the full handoff looks like this:
While the machine is off, the battery-powered RTC keeps the calendar alive.
When you boot, the operating system reads the RTC once to get a starting guess — a “seed” — for what time it is.
From that moment on, the OS hands timekeeping over to the faster main crystal, which is far more precise for short intervals.
As soon as there is a network, NTP corrects the whole thing over the internet, exactly as we are about to describe.
Notice the theme already creeping in: even your computer’s memory of time is just another small, imperfect clock that has to be corrected. The RTC is deliberately simple and uses almost no power, which means it is not very accurate — it drifts more than the main clock does. That is fine, because it only has to be a rough starting point until NTP takes over.
And when this little clock fails, you have probably seen the result. If that coin battery dies, the RTC forgets everything the instant you unplug the machine. On the next boot, it resets to some default — often midnight on January 1st of the year 1970 or 2000 — and suddenly nothing works right. Websites refuse to load with security warnings, because your browser thinks the site’s security certificate “isn’t valid yet” (your clock says it is 1970, decades before the certificate was issued). Builds fail, logs look insane, and the cause is a dead battery the size of a button.
Phones and laptops play the same game with a few extra helpers: a phone can also grab the correct time straight from the mobile network or GPS the moment it powers on, which is why your phone is right to the second even after the battery fully dies. Servers in a data center have an RTC too, but since they are always plugged in and constantly disciplined by NTP, the RTC mostly matters for that very first instant at boot.
The usual fix, and why the fix is also a problem
The standard cure for drift is to phone a friend who knows the correct time. That friend is a time server, and the protocol your computer uses to ask is called NTP (Network Time Protocol). Your machine asks “what time is it?”, gets an answer, and nudges its own clock to match.
Simple idea. The trouble is in the word “asks,” because asking happens over a network, and the internet does not deliver messages at a fixed speed.
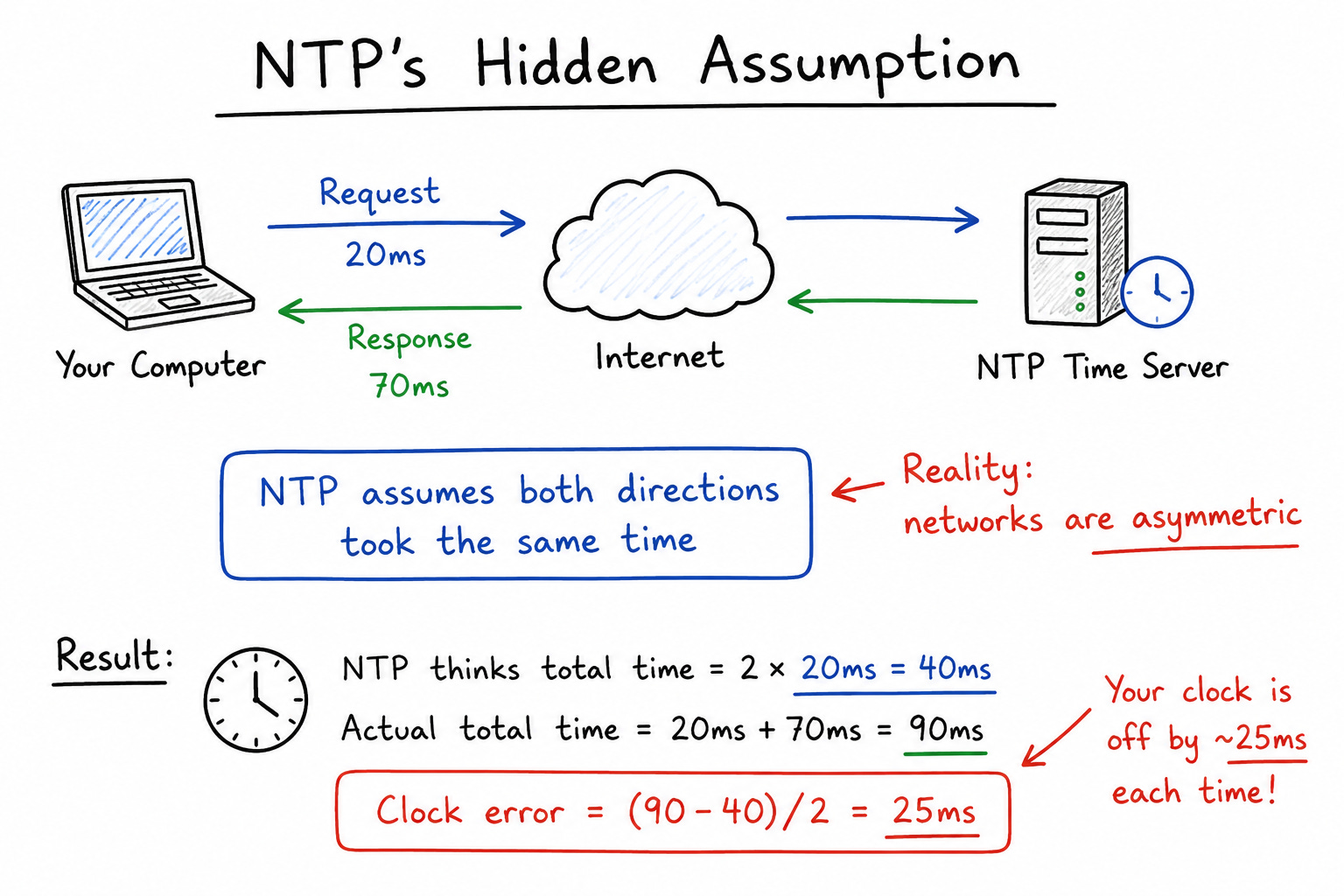
Think of the internet like the postal system. You mail a letter; it might arrive tomorrow, or it might sit in a sorting office for three days because of holiday traffic. Each letter is handled independently and waits in whatever queues it hits along the way. This is called a packet-switched network, and its delays are unpredictable and have no fixed upper limit.
(The old telephone system was different. When you made a call, the network reserved a dedicated wire from end to end for the whole conversation. That is a circuit-switched network, and its timing was steady and predictable. The internet gave up that predictability in exchange for being able to share one pipe among millions of people.)
Why does an unpredictable delay ruin time-keeping? Because of how NTP figures out the correct time. Your machine notes when it sent the question, the server notes the time in its reply, and your machine notes when the answer came back. To work out the true time, NTP has to guess how long the message spent traveling, and it guesses by assuming the trip out and the trip back took the same amount of time. When the network is congested, or the two directions are not equally fast, that assumption is wrong, and the wrongness leaks straight into your clock.
So the tool we use to correct drift comes with its own built-in error. You cannot escape it; you can only make it smaller.
On top of all that, the time server itself might just be wrong — misconfigured, overloaded, or broken. NTP people have a wonderful name for a server that confidently reports the wrong time: a falseticker.
A true story: the night time went backwards
Here is the example that makes all of this real.
On New Year’s Eve heading into 2017, the world’s official time added a leap second. Leap seconds are occasional one-second adjustments that keep our clocks lined up with the Earth’s slightly irregular spin. Most people never notice them. Computers, unfortunately, do.
At exactly midnight UTC, Cloudflare — a company that runs a huge slice of the internet’s plumbing — had part of its system fall over. Some websites using their service started failing DNS lookups (the step that turns a domain name into an address your browser can reach).
The cause was beautiful in how small it was. Cloudflare had code that measured how fast its internal servers were responding. It did this the obvious way: record the time before, record the time after, subtract one from the other to get a duration. A duration can never be negative... right?
But the leap second made the clock appear to step backwards by one second. So for one unlucky moment, the “after” time was earlier than the “before” time, and the subtraction produced a negative number. That negative number flowed into code that absolutely did not expect it (it was written in Go, and a function it called panics when handed a negative value), and servers started crashing.
The fix was a single character. The code checked whether a value was exactly zero; they changed it to check whether the value was zero or less. One < saved the day.
The lesson Cloudflare drew from their own outage is the whole point of this post: the bug was the belief that time can only move forward. It usually does. But “usually” is not “always,” and distributed systems live in the gap between those two words.
The rule that would have prevented it: two kinds of clocks
This story points at a fix that every engineer should know. There are really two different clocks on your machine, and they are good at two different jobs.

The first is the wall clock. This is the one that knows it is 3:47 PM on a Tuesday. In JavaScript that is Date.now(). It is the right tool when you need a real calendar time — a timestamp on a log line, an expiry date, “this was posted at 9 AM.” But it is the clock NTP corrects, which means it can jump, and it can move backwards.
The second is the monotonic clock. This one does not know what day it is and does not care. It only promises one thing: it always counts forward, at a steady rate, and never jumps. In JavaScript that is performance.now(); in Node you can also use process.hrtime.bigint(). Its starting point is meaningless (often it is just “time since the machine booted”), so you can never turn it into a calendar date. But for measuring how much time passed, it is bulletproof.
Here is the trap and the fix side by side:
// WRONG — measuring elapsed time with the wall clock.
// An NTP correction or leap second can make this negative or nonsense.
const start = Date.now();
doWork();
const elapsed = Date.now() - start;
// RIGHT — the monotonic clock never jumps backwards.
const start = performance.now();
doWork();
const elapsed = performance.now() - start;The simple rule: use the wall clock to answer “what time is it,” and the monotonic clock to answer “how much time has passed.” Mixing these up is one of the most common time bugs in the wild, and it is exactly what bit Cloudflare.
Why a few milliseconds can ruin your day
You might think a few milliseconds of disagreement between machines is nothing. In a single program, it is nothing. Across a fleet, it can decide who is in charge.
Imagine you schedule a job to run “at exactly midnight” on ten servers, and you want only one of them to actually do it. Each server checks its own clock. But machine A thinks it is already midnight while machine B is still two seconds behind. Now two servers both believe it is their turn. You get the job running twice — maybe two emails to every customer, maybe two charges on a credit card, maybe two machines both convinced they are the leader and each undoing the other’s work.
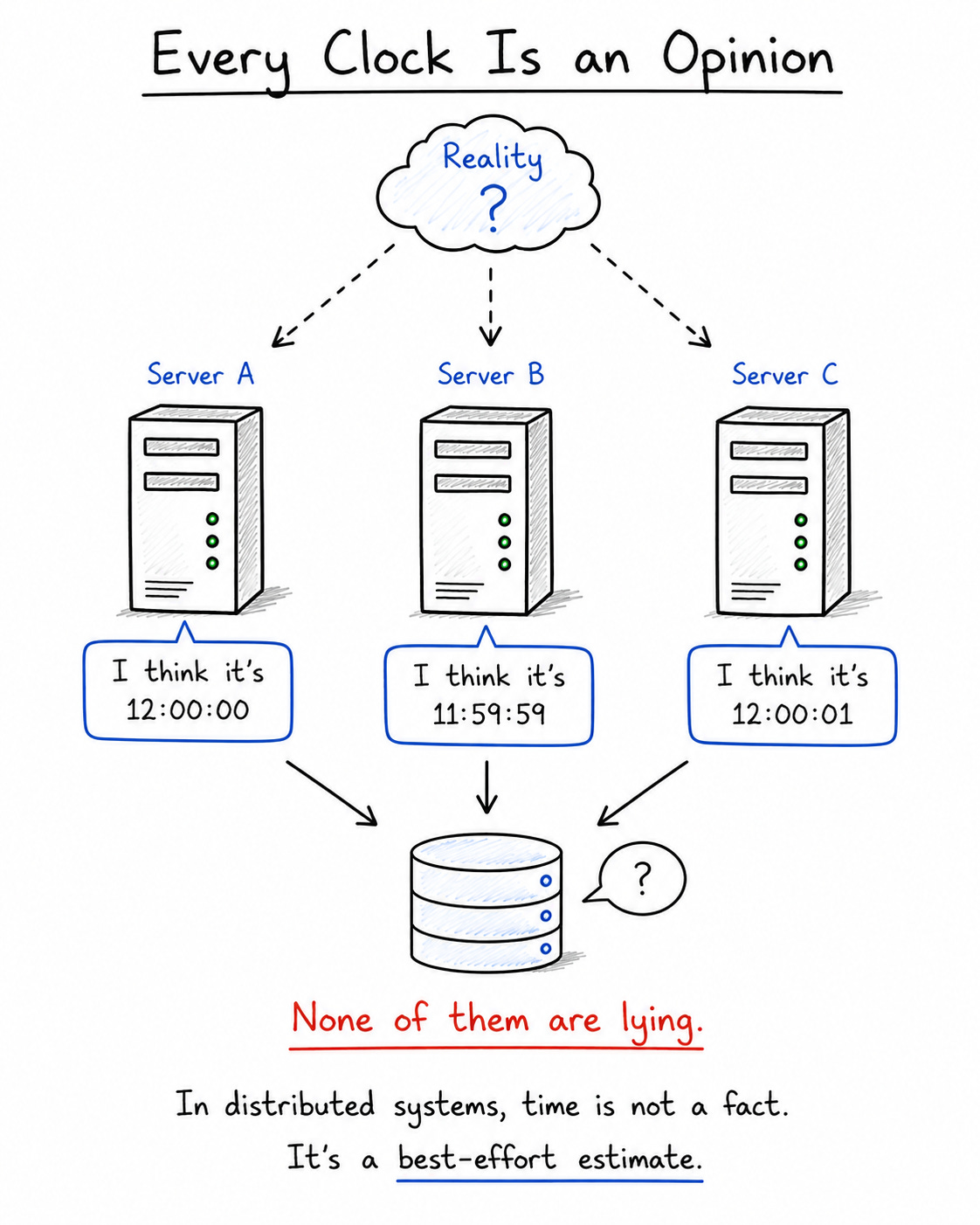
This is the heart of why time is dangerous in distributed systems. It is not that any one clock is badly broken. It is that no two clocks perfectly agree, and a surprising amount of code is secretly assuming they do.
How the big systems fight back
You cannot make this problem disappear, but you can shrink it. There are two common moves.
Move one: ask many clocks and ignore the liars. Instead of trusting a single time server, your machine asks several and throws out the ones that disagree with the majority. If four servers say it is 3:00 and one insists it is 3:05, you drop the oddball — the falseticker — and trust the crowd. Real NTP software (ntpd, chronyd) does this automatically on every check. It is cheap and good enough for the vast majority of systems.
There is also a gentler trick for leap seconds called smearing. Instead of adding the extra second in one sudden jump, you spread it across many hours by running every clock imperceptibly slow for a while. No clock ever jumps or goes backwards — it just glides into the new time. Google does this, and after their 2017 incident, Cloudflare adopted it too. It is a great example of fixing a problem by smoothing the time source instead of trusting it blindly.
Move two: buy better clocks and put them in your own building. If your NTP error comes from the long, noisy trip across the internet to a faraway time server, then put a very accurate clock right there in your data center so the trip is short and clean. The most famous example is Google’s database, Spanner, and its time system, TrueTime.
Google installed atomic clocks and GPS receivers in every data center. (They use both kinds on purpose: an atomic clock and a GPS receiver fail for completely different reasons, so it is very unlikely both go wrong at the same moment.) But the truly clever part is not the hardware — it is the honesty.
Normal clocks hand you a single number and pretend it is exact. TrueTime refuses to pretend. When you ask it the time, it gives you back a small range — something like “it is somewhere between these two moments, and I promise the true time is inside this window.” That window is usually just a few milliseconds wide. Instead of hiding its uncertainty, TrueTime measures and reports it.
Then Spanner does something delightfully simple with that range. When it wants to commit a piece of data in the correct order relative to everything else, it looks at its uncertainty window and deliberately waits until that window has fully passed before declaring the work done. It is literally waiting for time to catch up so it can be certain about ordering. This costs a few milliseconds on every write — that wait is the price of being correct. As the engineers put it, the wait turns uncertainty into a little bit of latency, and that trade is worth it.
The deep idea here is worth holding onto: you do not defeat clock uncertainty by pretending it is zero. You defeat it by measuring it, putting a firm number on it, and designing around that number.
This power is not free. The atomic clocks Google uses cost anywhere from tens of thousands to hundreds of thousands of dollars each, times every data center, plus the GPS gear and the people to maintain it all. That is exactly why this approach is reserved for systems that genuinely need it.
The one mindset to keep
If you remember nothing else, remember this. When you write code on a single computer, the clock is a fact. When you write code across many computers, the clock is an opinion — your machine’s current best guess at the time, formed from a drifting crystal and corrected over an unreliable network, capable of being wrong and even of running backwards.
Good distributed systems are built by people who treat time with suspicion:
They use the wall clock only for calendar timestamps, never for measuring how long something took.
They use the monotonic clock for durations and timeouts, because it never jumps.
They never assume two machines agree on the time.
When ordering truly matters, they either pin down the uncertainty with strong clocks (like TrueTime) or stop relying on physical time altogether and use other ordering tricks instead.
Time feels like the most solid thing in the world. In a distributed system, it is one of the softest. The engineers who ship reliable systems are simply the ones who never forgot that the clock can lie.
Further reading
The two stories at the heart of this post come straight from the people who lived them. Both are worth reading in full.
Cloudflare — the leap-second outage
How and why the leap second affected Cloudflare DNS — Cloudflare’s own post-mortem, including the line “a number went negative when it should always have been, at worst, zero,” and the one-character fix.
Google — Spanner and TrueTime
Spanner: Google’s Globally-Distributed Database — the original paper describing TrueTime, the
[earliest, latest]uncertainty interval, and the “commit wait” trick.Spanner wins the 2025 ACM SIGMOD Systems Award — a shorter, more recent retrospective from Google on how TrueTime turns clock uncertainty into a guarantee.
💡 If time can lie, what about randomness? Turns out the other primitive you trust blindly isn't so trustworthy either. Do check this out if this post got you excited: Math.random() is not so random: The Illusion of Randomness in JavaScript.
Before you go 👋
If you enjoyed this article, check out my book, Digital Footprint for Software Engineers. Your purchase fuels hope! 🎗️
Cool artical