
The AI-Native Backend: How LLMs Are Changing API Design
A developer's guide to building backends that serve humans and machines without going broke.

Most backend engineers are still building APIs like it’s 2019.
Request comes in. Database query runs. JSON goes out. 200 OK. Done.
Clean. Predictable. Fast. The kind of architecture you could reason about on a whiteboard in five minutes.
Then someone on the product team says, “We’re adding an AI feature.”
And everything you knew about API design quietly becomes insufficient.
The Fundamental Shift Nobody Prepared For
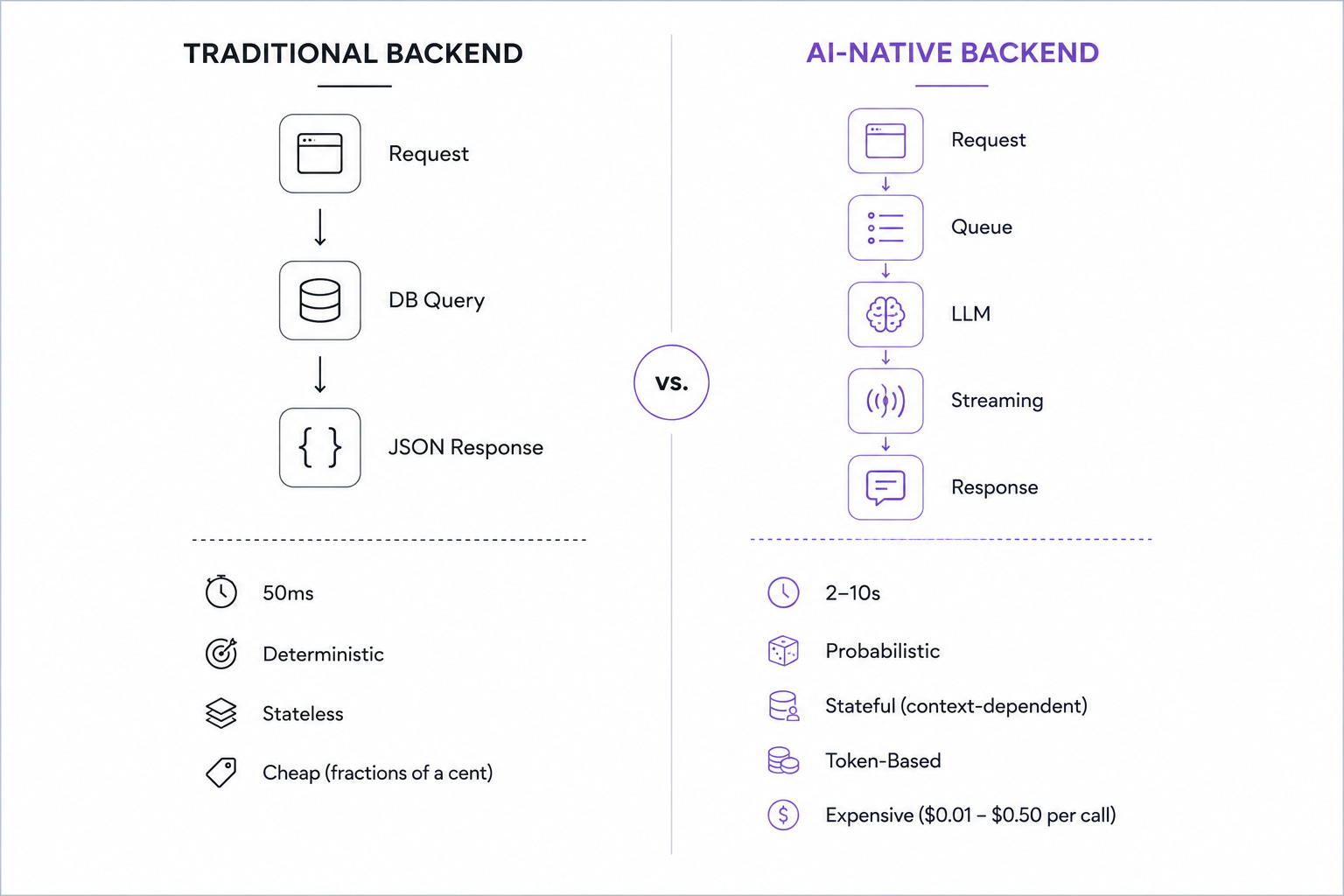
Traditional APIs are deterministic. Same input, same output, every time. A GET /users/123 returns the same user whether you call it at noon or midnight. Response time is measured in milliseconds. Cost per request is effectively zero. State is someone else’s problem.
LLM-powered endpoints are none of these things.
They are probabilistic — same input, different output, every time. They are slow — two to ten seconds instead of fifty milliseconds. They are expensive — every request has a measurable cost in dollars, not just compute. And they are stateful in ways that break every assumption your existing middleware was built on.
The table looks something like this:
Traditional API:
Request → Response.
50ms.
Deterministic.
Stateless.
Fractions of a cent.
LLM Endpoint:
Request → Queue → Stream → Response.
2,000–10,000ms.
Probabilistic.
Context-dependent.
$0.01–$0.50 per call.
This isn’t an incremental change. It’s a category shift. And most backend architectures were never designed to handle it.
If you’re building AI-powered features on top of a traditional REST backend without rethinking the fundamentals, you’re not scaling. You’re accumulating invisible debt.
Streaming Is the New Default
Here’s the first thing that breaks: your response model.
A traditional API returns a complete response. The client waits, gets the full payload, renders it. Simple.
An LLM generates tokens one at a time. The full response might take eight seconds. If your API makes the user stare at a loading spinner for eight seconds, you’ve already lost them. Perceived latency kills products faster than actual latency.
Streaming changes the contract between your backend and your client.
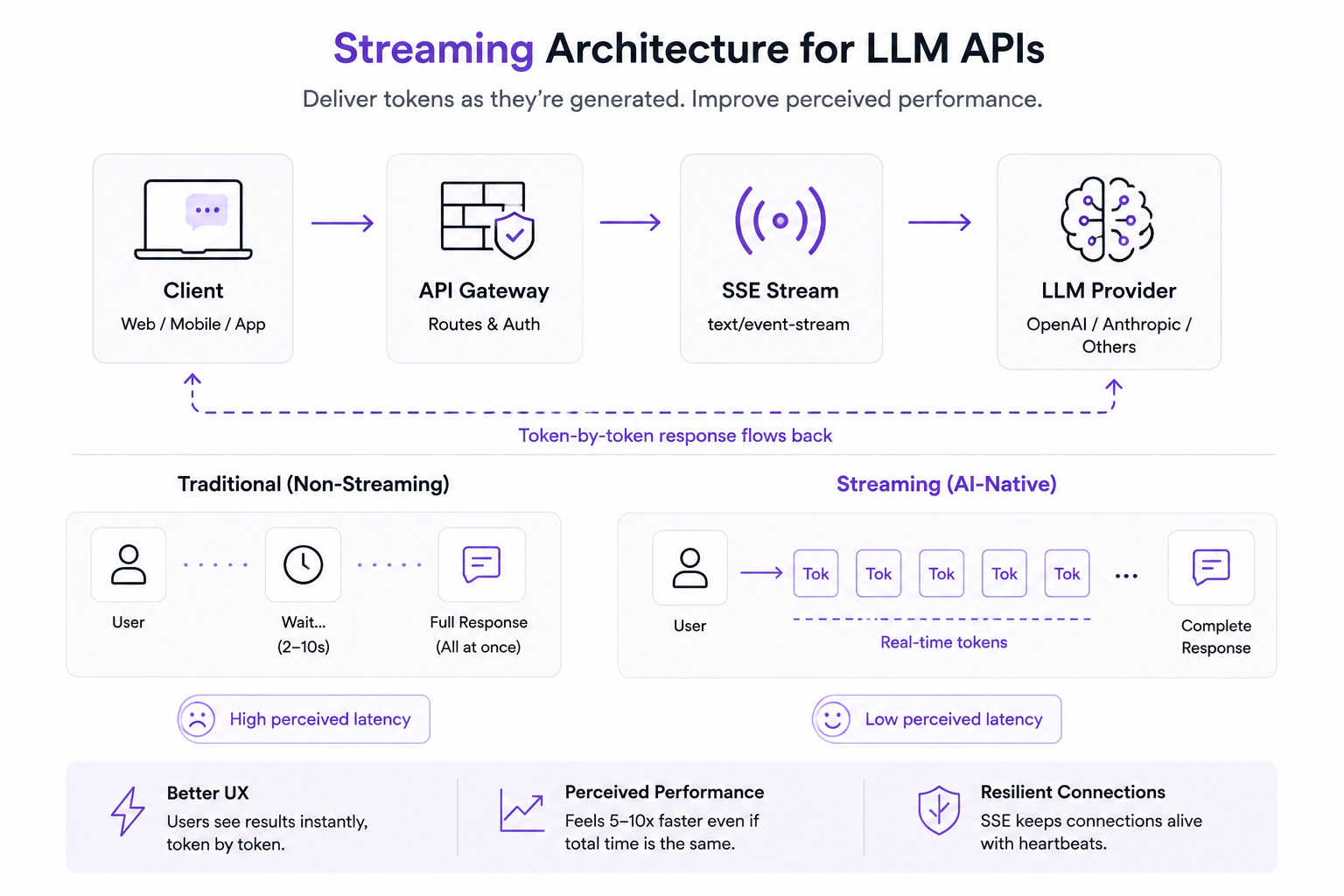
Instead of Content-Type: application/json, you’re now dealing with Content-Type: text/event-stream. Instead of a single response, you’re sending a sequence of Server-Sent Events (SSE), each carrying a chunk of the model’s output as it’s generated.
This sounds simple. It isn’t.
Your load balancers need to support long-lived connections. Your reverse proxy timeout settings — the ones nobody has touched since the initial setup — will silently kill streaming connections after 30 seconds. Your API gateway metrics, built around request-response pairs, don’t know how to measure a connection that stays open for twelve seconds and sends forty-seven chunks.
Your error handling model changes too. In a traditional API, errors are clean. 4xx or 5xx, the client knows what happened. In a streaming response, the connection might succeed, send half the output, and then fail. The client now has partial data. Is it usable? Is it corrupted? Your backend needs to signal this clearly — and most don’t.
The engineers who get this right treat streaming as a first-class architectural concern. Not a bolt-on. Not “we’ll add SSE later.” From day one: chunked responses, heartbeat signals, graceful partial failure, and client-side buffering strategies.
Your Rate Limiter Is Counting the Wrong Thing
Traditional rate limiting counts requests. 100 requests per minute per user. Simple. Fair. Done.
This completely breaks with LLM endpoints.
Consider two users. User A sends 10 requests, each with a 500-token prompt. User B sends 10 requests, each with a 50,000-token prompt. Under request-based rate limiting, they’re identical. Under reality, User B is consuming 100x the resources and costing you 100x the money.
The unit of scarcity changed. It’s no longer requests. It’s tokens.

An AI-native backend needs token-aware rate limiting. This means tracking input tokens, output tokens, and — if you’re using reasoning models — thinking tokens, which are billed as output but invisible to the user.
The implementation looks something like this: every request to your LLM proxy passes through a middleware that estimates input token count before the call, then records actual usage from the model’s response metadata after the call. Both counts get decremented from the user’s token budget — which resets daily, weekly, or monthly depending on your billing model.
This is more complex than a Redis counter. It requires per-user token accounting, real-time budget enforcement, and a decision about what happens when a user exceeds their allocation mid-stream. Do you cut the response? Queue it? Downgrade to a cheaper model?
These aren’t theoretical questions. They’re product decisions that your backend architecture needs to support.
Caching LLM Responses Is a Solved Problem That Nobody Solves
Traditional caching is straightforward. Same URL, same parameters, same response. Cache it. Invalidate it when the data changes. Redis, CDN, done.
LLM caching is harder because natural language is fuzzy. “What’s your return policy?”, “How do I get a refund?” and “Can I send this back?” are three different strings that mean exactly the same thing. An exact-match cache misses all of them.
This is where semantic caching enters the picture.
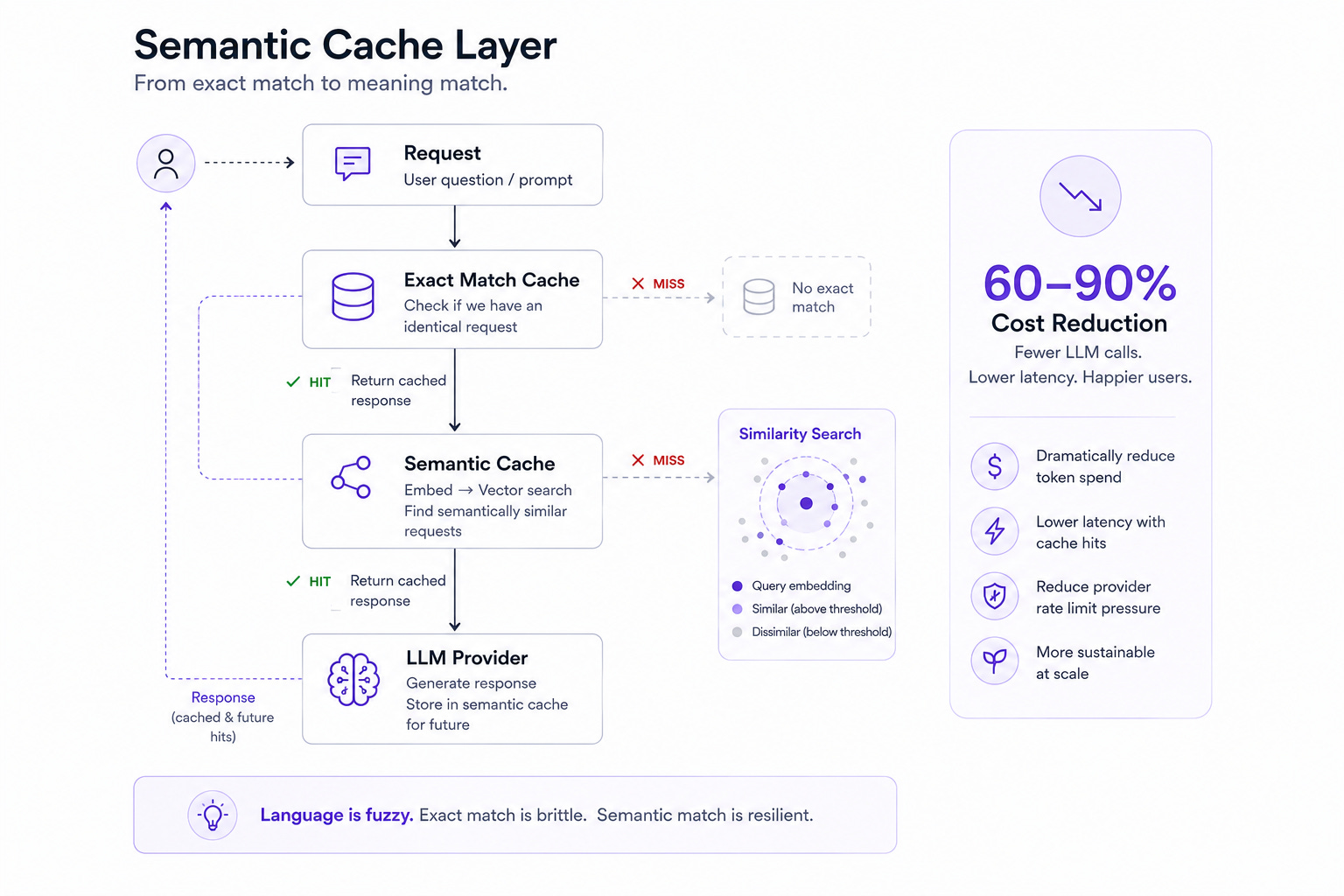
Semantic caching embeds the input prompt into a vector, stores it alongside the response, and on subsequent requests, performs a nearest-neighbor search. If the new prompt is semantically similar enough — above a configurable cosine similarity threshold — the cache returns the stored response. The LLM is never called.
Production hit rates on semantic caches typically land between 30–70% for FAQ-style traffic and agent workflows. At scale, this is the difference between a manageable API bill and a financial emergency.
The architecture is layered. Exact-match cache sits at the top — cheapest, fastest, handles identical prompts. Semantic cache sits below it — catches paraphrases and near-duplicates. Provider-level prompt caching (like Anthropic’s) sits at the bottom — reduces per-token cost for cache misses by caching shared prefixes.
Stack all three and you’re looking at a 60–90% reduction in LLM API spend. This isn’t optimization. It’s a different economic model.
The teams that don’t implement this discover the problem the hard way — usually when the first real invoice arrives.
Prompt Versioning: Treat Prompts Like Code
Here’s a mistake I’ve seen in every AI-powered backend I’ve audited: prompts stored as inline strings.
Hardcoded in the route handler. Buried in a utility function. Copy-pasted across three microservices with subtle differences between each.
Prompts are not strings. Prompts are business logic. When a prompt changes, your application’s behavior changes. When it changes silently, your application’s behavior changes silently. This is the definition of a production incident waiting to happen.
The solution is the same pattern we already know: version control.
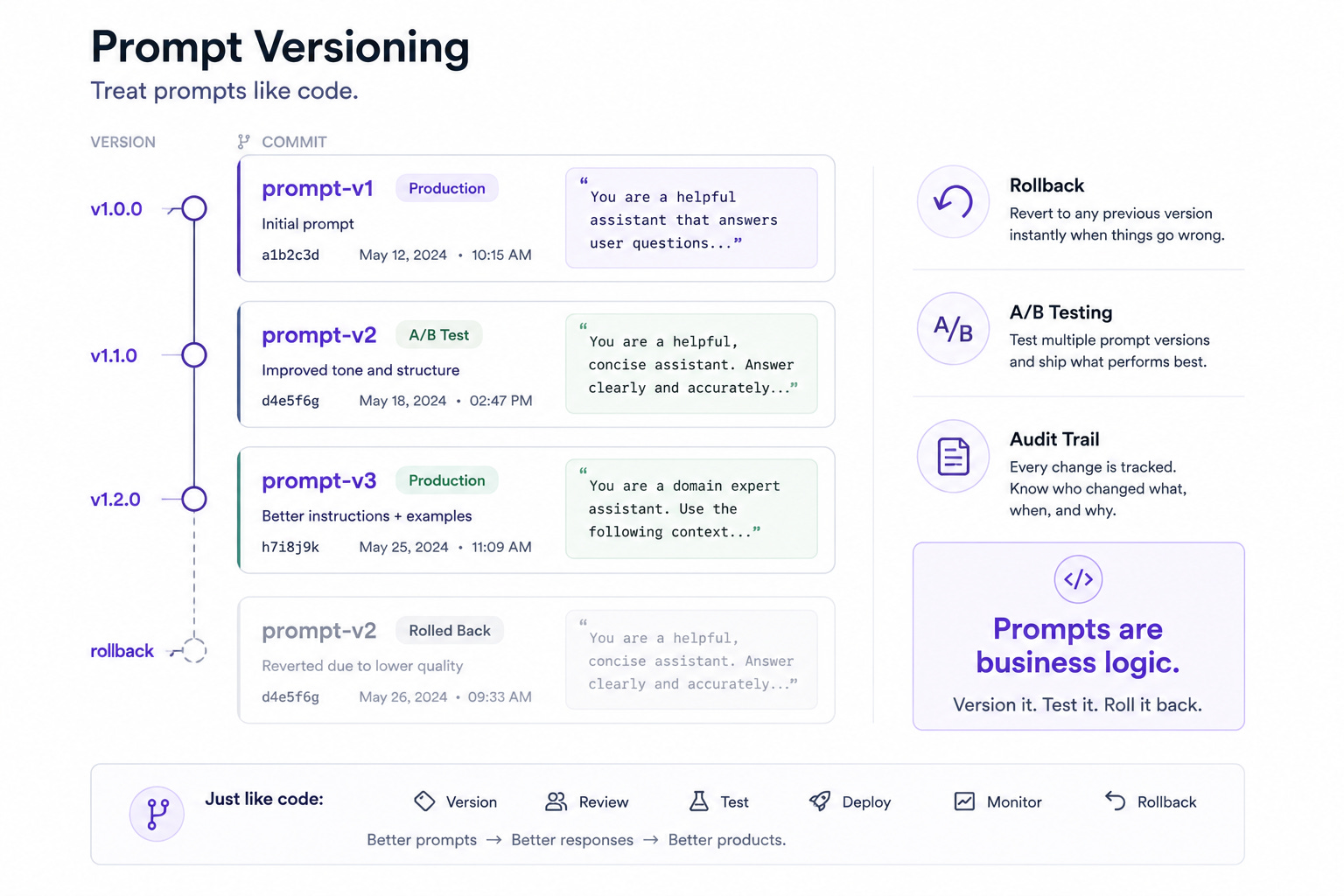
Build a prompt registry. Each prompt has an ID, a version, a template with variable interpolation, and metadata — who changed it, when, and why. Store it in your repo, not your database. Review prompt changes in pull requests, not Slack threads. A/B test prompt variants with traffic splitting, the same way you’d test a new algorithm.
This gives you three things you can’t get otherwise: rollbacks when a prompt regression hits production, audit trails for debugging, and the ability to measure which prompt version performs better against your evaluation metrics.
The engineers who treat prompts as configuration end up with fragile systems. The ones who treat prompts as code end up with systems they can reason about.
Graceful Degradation: What Happens When the Model Goes Down
Traditional backends degrade in predictable ways. Database slow? Queries queue up. Third-party API down? Circuit breaker trips, fallback kicks in.
LLM providers go down differently. Rate limits hit without warning. Latency spikes from two seconds to thirty. The model returns a valid response that is completely wrong. And because you’re often calling a third-party API — Anthropic, OpenAI, or a self-hosted inference endpoint — you control none of the underlying infrastructure.
An AI-native backend needs a degradation strategy that assumes the LLM is unreliable.
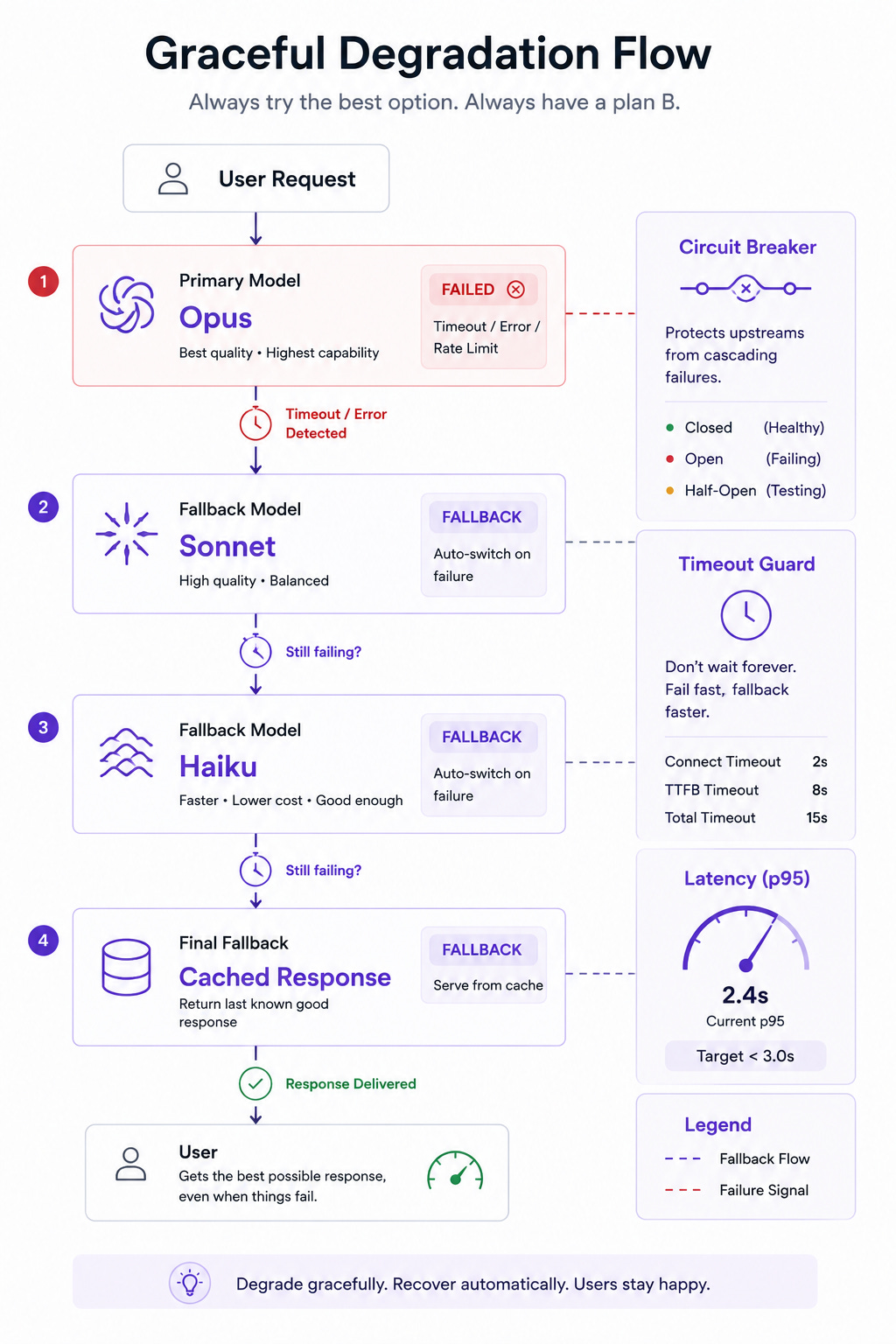
This means circuit breakers that trigger on latency, not just errors. A request that takes twenty seconds to return a response is functionally equivalent to a timeout for most user-facing products. Your circuit breaker should treat it that way.
It means model fallbacks. If Opus is overloaded, fall back to Sonnet. If Sonnet is down, fall back to Haiku. If everything is down, fall back to a deterministic response — a cached answer, a template, a “we’re working on it” message. Anything is better than a loading spinner that never resolves.
It means retry logic that understands token economics. Retrying a failed LLM call isn’t free — you’re paying for the tokens again. Exponential backoff needs to factor in cost, not just time.
And it means timeout budgets that are calibrated to LLM latency. If your global request timeout is five seconds because that’s what your REST API needs, every streaming LLM response will get killed mid-generation. Set per-route timeouts. Give LLM endpoints thirty to sixty seconds. Give your traditional endpoints the tight timeouts they deserve.
Your API Now Serves Two Species
This is the shift that most backend engineers haven’t internalized yet.
Your API used to serve one consumer: humans, via a frontend client. The contract was simple. A browser or mobile app sends a request. Your backend responds with JSON. A human reads the rendered result.
Now your API serves two consumers: humans and machines.
AI agents — Claude Code, Codex, Cursor, custom agentic workflows — are calling APIs autonomously. They discover endpoints at runtime. They read schemas dynamically. They chain calls together without human intervention.
The Model Context Protocol (MCP) is the clearest signal of this shift. MCP, originally built by Anthropic and now governed by the Linux Foundation, standardizes how AI agents discover and invoke tools. By mid-2026, MCP has crossed 97 million monthly SDK downloads. OpenAI deprecated its proprietary Assistants API in favor of MCP. Every major AI provider supports it.
What this means for your backend: your API needs to be legible to machines, not just documented for humans.
Machine-legible means structured tool schemas that agents can parse at runtime. It means predictable error formats — not vague 500 responses, but structured error objects that an agent can reason about and retry intelligently. It means response shapes that are consistent enough for an LLM to parse without hallucinating the structure.
Think of it as the difference between writing documentation for a junior developer and writing a type-safe interface for a compiler. The junior developer can handle ambiguity. The compiler cannot. Agents are closer to compilers.
If you’re building a backend in 2026 and you’re not thinking about agent consumption, you’re building for yesterday’s traffic.
Cost Observability: The New Monitoring Layer
In traditional backends, monitoring means latency, error rates, throughput, and saturation. The standard four golden signals. You know the dashboard.
AI-native backends need a fifth signal: cost per request.
Every LLM call has a dollar amount attached to it. And unlike compute costs, which are amortized across millions of requests, LLM costs are per-call, per-token, and highly variable. A single poorly constructed prompt can cost more than a thousand traditional API calls.
Your observability stack needs to track, for every LLM call: model used, input tokens, output tokens, thinking tokens, latency, and cost in dollars. Not aggregated daily. Per request. In real time.
This data feeds three critical functions. First, alerting — if a single endpoint’s LLM cost spikes 10x because someone changed a prompt, you need to know in minutes, not at the end of the billing cycle. Second, attribution — which feature, which user, which prompt version is driving the bill. Third, optimization — you can’t reduce what you can’t measure.
The engineers who build cost observability from day one make informed tradeoff decisions. The ones who bolt it on after the first invoice make panicked ones.
The Architecture That Emerges
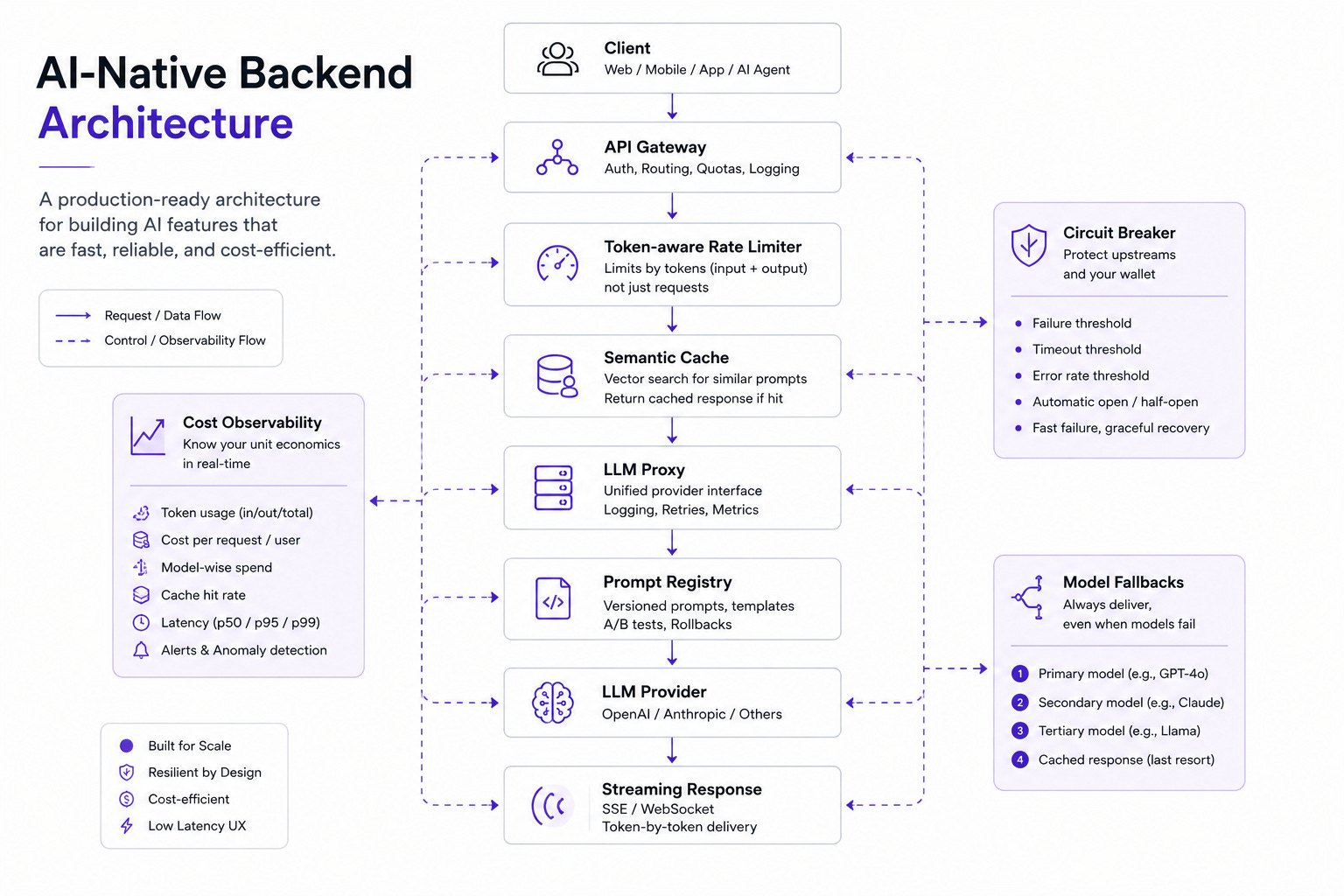
When you combine these patterns, a clear architecture emerges. It looks nothing like a traditional REST backend with an LLM call bolted on.
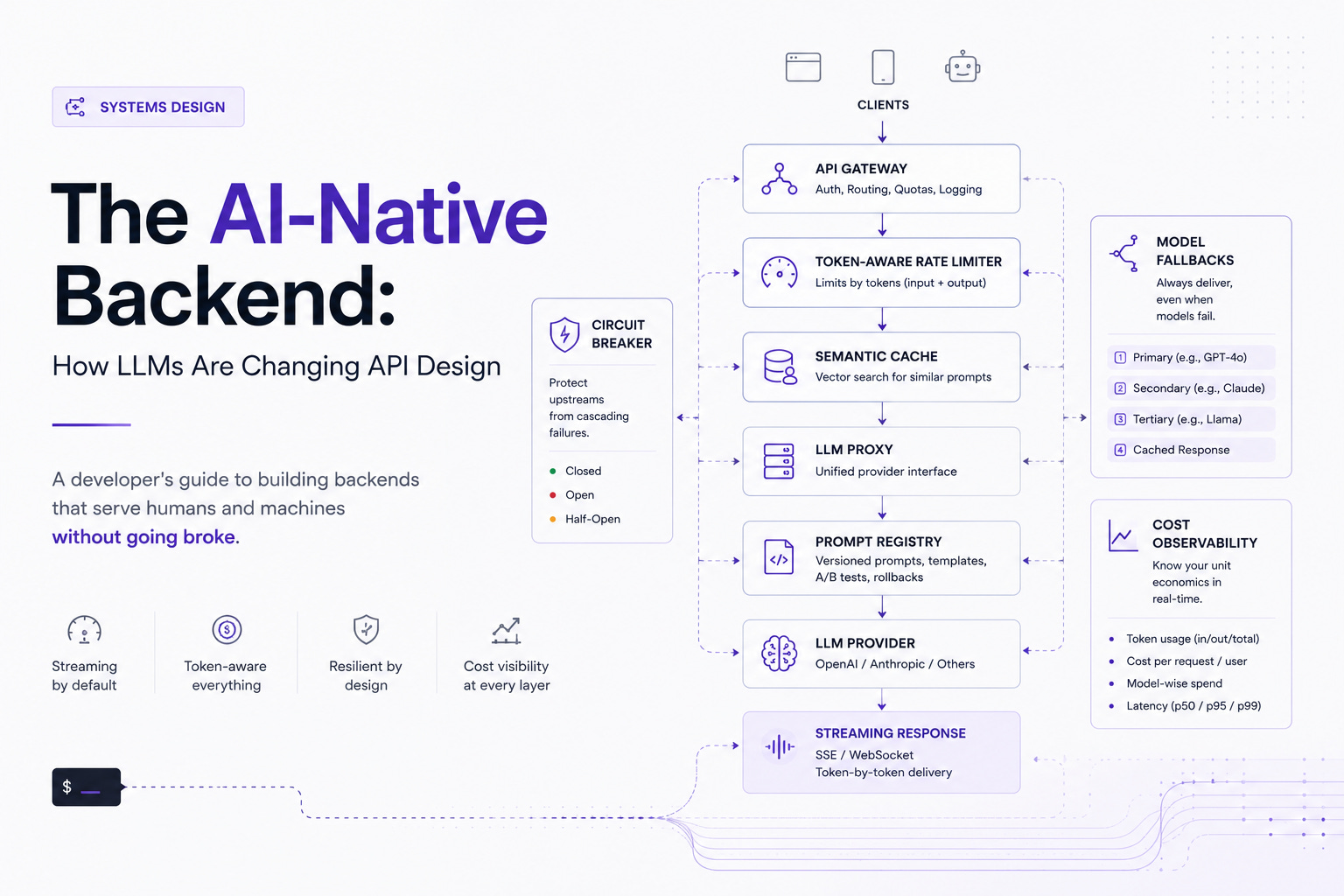
The request arrives at your API gateway. A token-aware rate limiter checks the user’s budget. The request passes through a semantic cache layer — if there’s a hit, the response returns in single-digit milliseconds and the LLM is never called.
On a cache miss, the request reaches your LLM proxy. The proxy selects the appropriate model based on task complexity, retrieves the versioned prompt template, injects context, and initiates a streaming call to the provider.
The response streams back through your backend to the client via SSE. A cost tracker logs the exact token usage and dollar amount. The response gets written to the semantic cache for future hits. If the call fails mid-stream, a circuit breaker triggers, and the fallback path returns a cached or deterministic response.
Every layer is independently observable. Every layer degrades gracefully. Every layer understands that the unit of currency is tokens, not requests.
This is what an AI-native backend looks like. Not a REST API with a /chat endpoint. A system designed from the ground up around the economics and constraints of language models.
The Uncomfortable Truth
Most teams building AI features today are wrapping a single fetch call to an LLM provider inside an Express route handler and calling it a day.
It works. Until it doesn’t.
Until the first $5,000 invoice arrives and nobody can explain which feature caused it. Until the model goes down for twenty minutes and your entire product goes down with it. Until an agent starts calling your API in a loop because your error format was ambiguous.
The backend patterns that served us for a decade — stateless request-response, request-count rate limiting, exact-match caching, synchronous responses — were designed for a different world. A world where compute was expensive and API calls were cheap. We now live in the inverse. Compute is cheap. Intelligence is expensive. And every call to an LLM has a price tag that your architecture needs to respect.
The engineers who understand this will build systems that scale. The ones who don’t will build systems that go bankrupt.

Same tools. Same languages. Different thinking.
That’s always where the leverage is.
Great breakdown, Really liked your points on token-aware rate limiting, semantic caching, and the full AI-native architecture.
For a 1-2 dev team building an MVP though, I’m wondering if starting simpler (direct streaming calls + lightweight setup) might be better for velocity, then evolving into this more robust system once usage grows. Curious how you think about that early-stage tradeoff